

これまで、「日経ソフトウェア」の特集「HTML5でゲームを作ろう!」を見ながら、エディタ(最近はBlueFishを使用)で、HTMLファイルとJavaScriptファイルを書き起こしていました。
毎回、文字入力するのが面倒になり、疲れていると入力ミスも増えるので、スキャナで読み込んだイメージデータを、OCRソフトでテキストに変換して使えるか試してみました。
(1)「OCRFeeder」をインストール
 OCRソフトには、Ubuntuソフトウェアセンターから「OCRFeeder」をインストールして使用しました。
OCRソフトには、Ubuntuソフトウェアセンターから「OCRFeeder」をインストールして使用しました。
OCRエンジンとして「Tesseract-OCR」がインストールされます。
しかし、そのままでは日本語には対応していないので、日本語の学習データをダウンロードします。
(2)日本語の学習データをコピー
以下のサイトにアクセス。
https://code.google.com/p/tesseract-ocr/downloads/list
サイト上部の検索部分に「Japanese」を入力して「search」ボタンを押すと該当ファイルが絞りこまれます。
今回は「tesseract-ocr-3.02.jpn.tar.gz」をダウンロードしました。
解凍して、フォルダ内にある「jpn.traineddata」ファイルを、「Tesseract-OCR」の tessdata フォルダにコピーします。
tessdataの場所は、 updatedbコマンド実行後、locateコマンドで検索。
(「eng.traineddata」ファイルが存在する・・・/tessdataフォルダにコピーします。)
$ sudo updatedb $ locate tessdata $ sudo cp ./jpn.traineddata /usr/share/tesseract-ocr/tessdata
(3)「OCRFeeder」で文字を読み取り
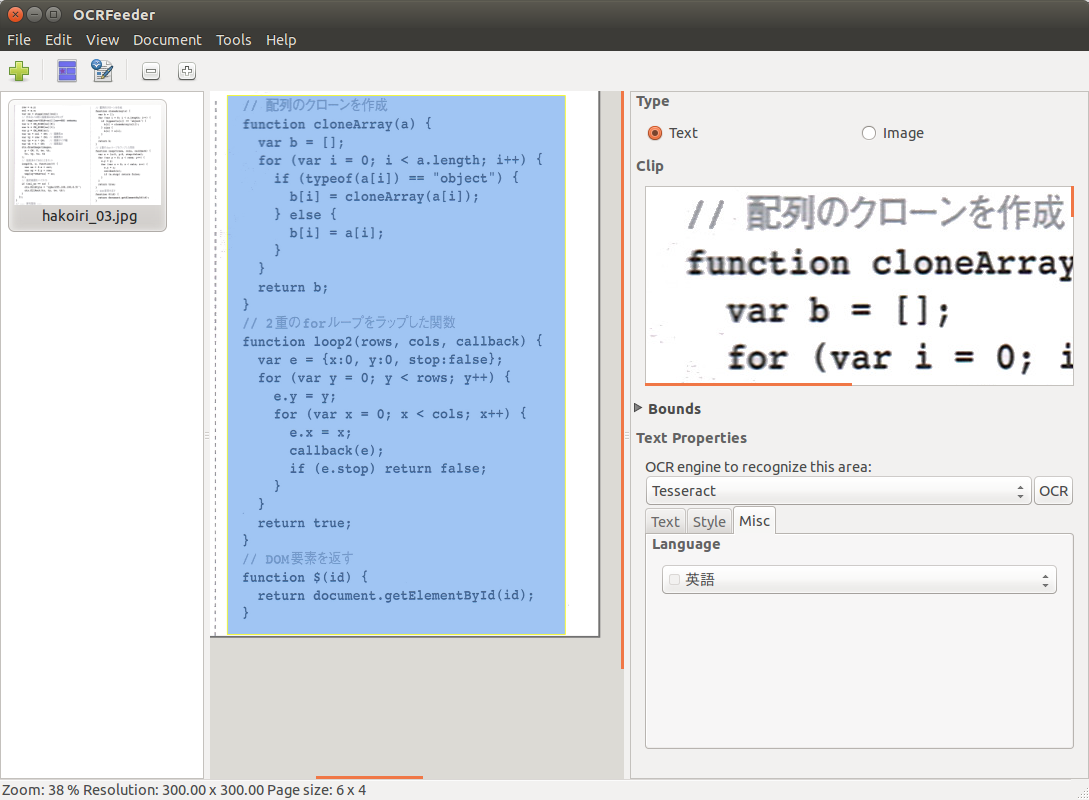 (3−1)英語でOCR
(3−1)英語でOCR
「+」アイコンを押し、スキャナで読み込んだイメージファイルを取り込む。
マウスでOCRの対象範囲を指定する。複数に分けて指定可能で、最後にクリックした範囲が、現在の変換対象となる(=外枠が黄色)。
右下の「Misc」タブで学習データ(文字のパターンデータ)が選択できる。デフォルトは「英語」。
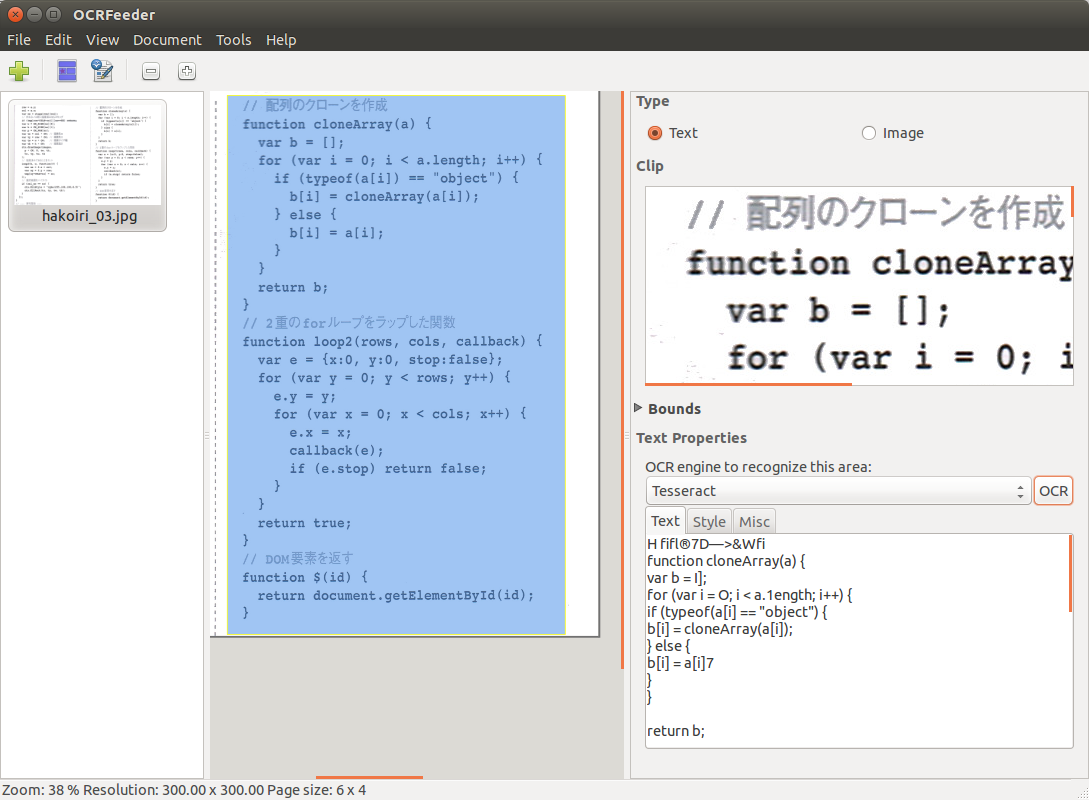 「Text」タブに切り替え、OCR engine の選択リストが「Tesseract」になっているところの右にある「OCR」ボタンをクリックします。
「Text」タブに切り替え、OCR engine の選択リストが「Tesseract」になっているところの右にある「OCR」ボタンをクリックします。
イメージを読み取り学習データとマッチした文字コードに変換してテキストエリアに表示します。
・・・英語部分はまあまあの精度で変換されていますが、日本語コメント部分は近似した英語を充てる為、全く使えません。
・・・英語の「l」が数字の「1」に、数字の「0」が英語の「O」や「o」に誤変換される場合が多くみられました。
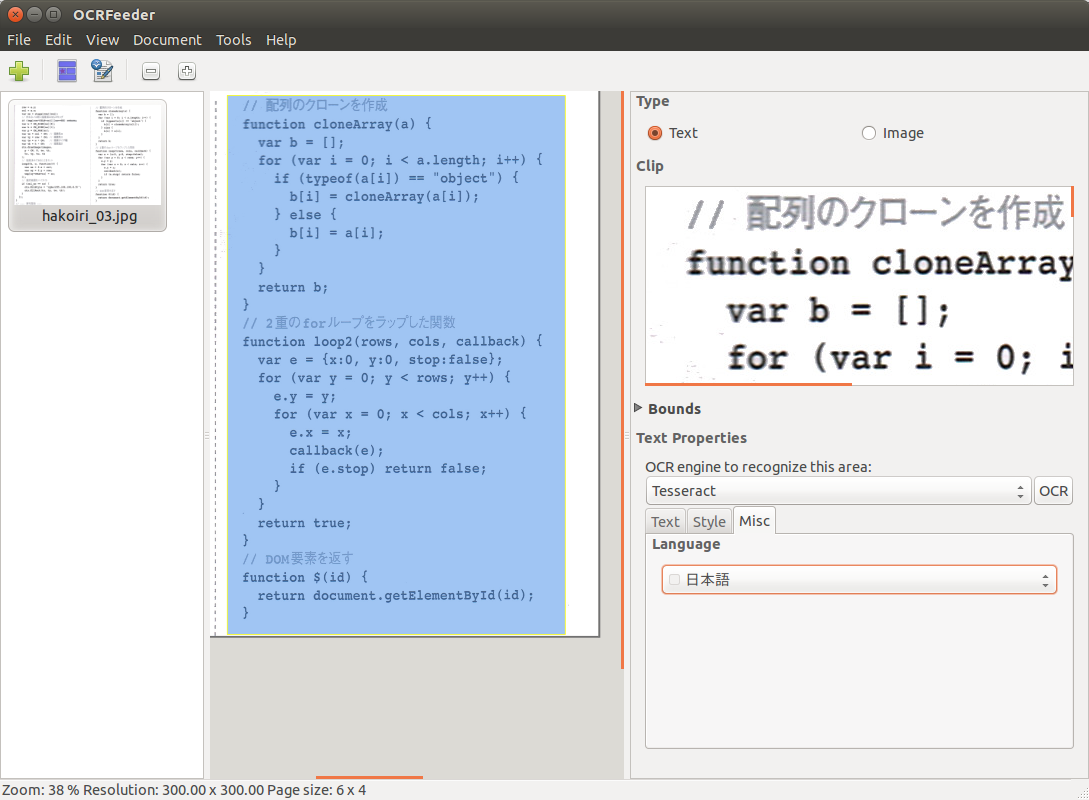 (3−2)日本語でOCR
(3−2)日本語でOCR
右下の「Misc」タブで学習データ(文字のパターンデータ)を「日本語」に変更。
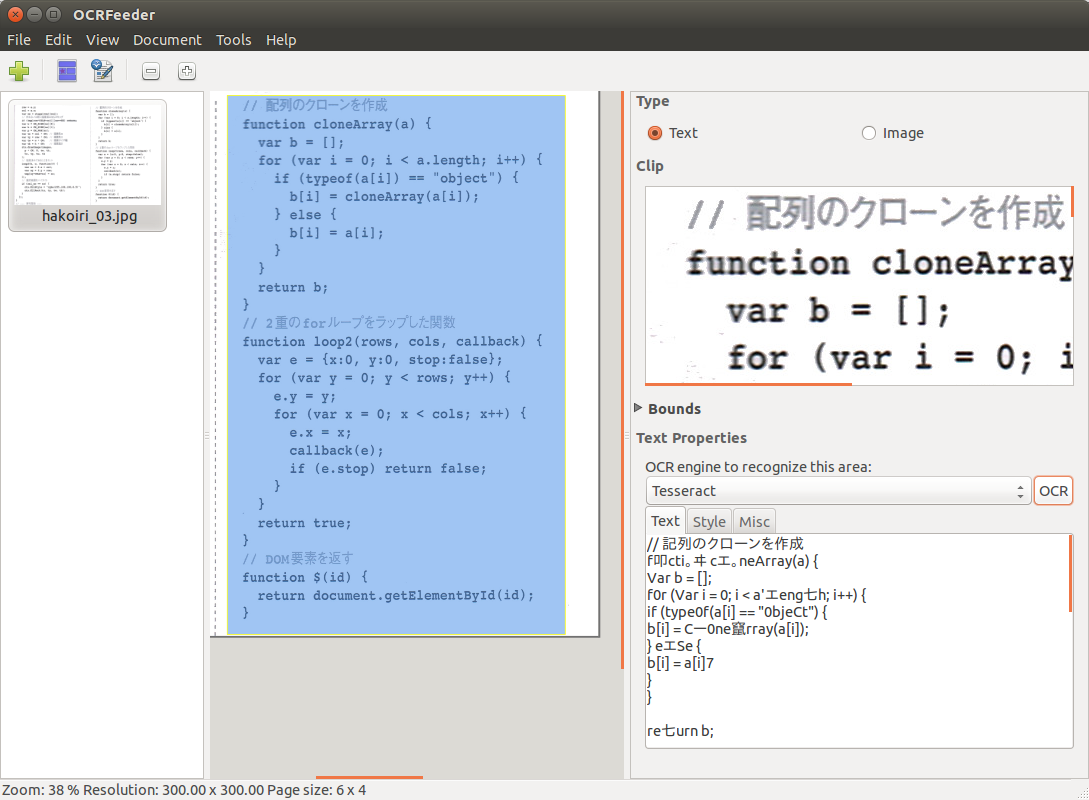 「Text」タブに切り替えます。
「Text」タブに切り替えます。
テキストエリア内に残っているテキストを全選択(Ctrl+A)後に削除(Del)します。
「OCR」ボタンをクリック。
・・・日本語部分はある程度の精度で変換されますが、英語部分は逆に使い物にならないようです。
・・・右の例では「配列」であるべきコメントが「記列」になってしまいました。
・・・スキャナで紙面をスキャンする際に、解像度(とコントラスト)をもう少し上げてやれば、変換精度も向上したと思われます。
今回は、ソースコード(半角英数字)部分は「Misc」タブで「英語」を選択して変換し、内容をテキストエディタへコピー&ペースト。
その後、日本語コメント部分は「Misc」タブで「日本語」を選択して変換し、日本語部分のみテキストエディタへコピー&ペースト。
最後に、テキストエディタ(BlueFish)内で誤変換部分を修正しました。
一応、使えることは使えましたが、手入力作業での「入力ミス」と、同程度のOCR「変換ミス」がありました。
単調なテキスト入力作業が不要となるのは嬉しいですが、OCR実行後の変換ミスを探し修正する作業が増えました。
まあ、使い続ければ、OCR変換ミスのクセが判ってくるでしょうから、問題ないかも知れません。
OCRで文字単位でパターンを比較し変換する精度を上げるのも大事でしょうが、変換後に、単語(ワード)単位ので整合性チェックを実施する仕組みを盛り込んでくれたら良いのに・・・と思ってしまいます。
そうすれば、例えば「sty1e」と言う単語はDBに存在しないから「style」が正しいと判断し自動的に修正(あるいは修正候補を表示)させる事ができるのでは・・・。
今回、プログラムのソースコード作成を簡略化したかった訳ですが、なかなか思い通りにはなりませんでした。
日経ソフトウェアのWebサイトでは、サンプルプログラムをダウンロードできるようになっていますが、残念ながら「HTML5でゲームを作ろう」に関しては公開されていないようです。
日経ソフトウェア(月刊誌)には電子版もあります。
電子版の閲覧には専用のビューアが必要です。
電子書籍のビューアは「著作権保護管理(DRM)システム」を採用しているものがほとんど。
イメージやテキスト等をコピー&ペーストしようとしても、キャプチャーできない仕組みになっています。
もし、ソースコード部分をコピー&ペーストして扱うことが可能なら、即座に、PC用(それも出来ればLinux用)ビューアが存在する書店から、電子版の書籍を購入するのですが・・・。